Bình luận
• 0 chia sẻ• 0 bình luận270 lượt xem
Bình luận
Tác giả: Trương Văn Trắc
Ngày cập nhật: 26/08/2024


1. Tùng
2. Kiên
3. My
4. Phương Anh
5. Miền Nam
6. Miền Trung
7. Miền Bắc

Data Pipeline còn được biết đến với tên gọi là đường ống dữ liệu. Đây là một loại phương pháp mà dữ liệu thô sẽ được nhập từ nhiều nguồn khác nhau. Ngay sau đó, nó sẽ được chuyển đến kho dữ liệu để thực hiện quá trình phân tích.
Trước khi dữ liệu được chính thức đưa vào kho, nó sẽ được thực hiện một khâu gọi là quy trình xử lý dữ liệu. Ở đây, nó sẽ được kết nối bởi nhiều bước chuyển đổi dữ liệu như lọc, che dấu dữ liệu, tổng hợp, đảm bảo sự tích hợp và tiêu chuẩn hóa bộ dữ liệu.
Ở kho dữ liệu này, chúng ta sẽ thấy được một biểu đồ yêu cầu phải có sự thống nhất với nhau. Nghĩa là, tất cả các cột hay loại dữ liệu phải có tính đồng nhất với nhau để dữ liệu cũ có thể dễ dàng kết nối với dữ liệu mới.
Data Pipeline thường được sử dụng như một “đường ống” cho các dự án khoa học về dữ liệu hay bảng thông tin liên quan tới kinh doanh. Dữ liệu sẽ được xuất phát từ nhiều nơi khác nhau như API, dữ liệu cơ sở SQL, tệp hay NoSQL,…
Tuy nhiên, những dữ liệu này khi được nhập vào sẽ không được sử dụng ngay. Thay vào đó, các nhà khoa học dữ liệu hoặc ds việc làm tuyển dụng kỹ thuật viên xử lý dữ liệu phải chuẩn bị một dữ liệu xây dựng cấu trúc để thực hiện một đề án kinh doanh.
Một hình thức xử lý dữ liệu sẽ được tạo ra nhờ sự kết hợp giữa quá trình phân tích dữ liệu và nhu cầu về kinh doanh. Ngay khi dữ liệu đã lọc, hợp nhất và tóm tắt một cách chuẩn xác, dữ liệu đó mới có thể được lưu trữ và hiển thị để sử dụng. Các Data Pipeline được tổ chức tốt sẽ cung cấp cho nền tảng của một dự án dữ liệu, có thể kể đến một vài cái tên như phân tích dữ liệu, tác vụ học máy và trực quan hóa dữ liệu.
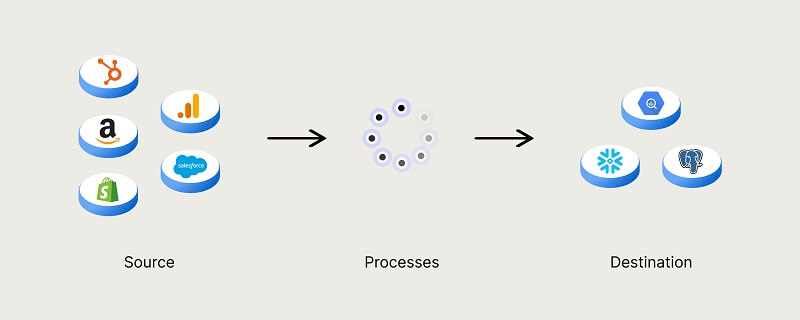
Trong những năm vừa qua, Data Pipeline đã dần khẳng định vị trí của mình trong nền khoa học máy tính khiến rất nhiều kỹ sư hay khoa học phải bắt tay vào thực hiện và tìm cách phát triển chúng. Các Data Pipeline thường được sử dụng rộng rãi trong việc nhập dữ liệu, tiến hành xử lý quá trình chuyển đổi dữ liệu thô sao cho hiệu quả. Tất cả vì mục tiêu tối đa hóa dữ liệu và được tái tạo liên tục hàng ngày.
Những dữ liệu đã được chuyển đổi sẽ được sử dụng cho Data Analytics, Machine Learning và một vài ứng dụng đặc biệt khác. Thông thường, Data Analytics sẽ được áp dụng trong một vài trường hợp phổ biến sau:
- Đưa ra thông tin căn bản cho bộ phận Sales và Marketing khi triển khai hệ thống CRM để cải thiện chất lượng dịch vụ khách hàng.
- Truyền dữ liệu lấy được từ cảm biến đến ứng dụng để theo hiệu suất hay trạng thái.
- Thống nhất toàn bộ dữ liệu với nhau để tăng tốc độ cho quá trình phát triển các sản phẩm mới.

Sự phát triển của Batch Processing đã trở thành một tiến trình quan trọng trong việc xây dựng cơ sở hạ tầng dữ liệu đáng tin cậy. Loại dạng Data Pipeline này đã bắt đầu xuất hiện vào năm 2024, khi có một thuật toán xử lý hàng loạt có tên là MapReduce. Nó đã mau chóng được cấp bằng sáng chế và được tích hợp trong một số hệ thống nguồn mở như Hadoop, Mongodb, Couchdb.
Batch Processing thường được áp dụng tại các doanh nghiệp có mong muốn di chuyển một khối lượng dữ liệu lớn vào trong kho dữ liệu với khoảng thời gian đều đặn. Thông thường, quá trình này sẽ được lên lịch vào ngoài giờ cao điểm nhằm giúp khối lượng công việc sẽ không bị ảnh hưởng do phải xử lý hàng loạt khối lượng di chuyển dữ liệu lớn.
Batch Processing sẽ là một đường dẫn dữ liệu tối ưu khi không cần phải thực hiện phân tích dữ liệu nhanh chóng. Nó sẽ thường có sự liên kết với quy trình tích hợp quy trình dữ liệu như ETL, viết tắt của Extract, Transform và Load.
Xem thêm: [ETL là gì?] - Cách thức hoạt động của ETL và tại sao lại cần tới
Streaming Data thường được sử dụng để xử lý dữ liệu được tạo ra liên tục bởi các nguồn hay yêu cầu xử lý ở ngay khi nó được tạo ra. Ví dụ thực tế như hệ thống điểm bán hàng cần dữ liệu thời gian thực để cấp nhật số lượng hàng tồn kho hay thời điểm bán của từng sản phẩm. Điều này sẽ giúp người bán biết được sản phẩm còn tồn tại ở kho hàng hay không.
Về cơ bản, hệ thống Streaming Data sẽ có tốc độ luồng nhanh hơn so với việc xử lý theo đợt bởi toàn bộ dữ liệu sẽ được tiến hành ngay khi vừa xảy ra. Tuy nhiên, cách làm này được xem là không đáng tin cậy do hệ thống xử lý theo đợt sẽ đôi khi bỏ sót các tin nhắn hay mất quá nhiều thời gian trong việc chờ đợi.
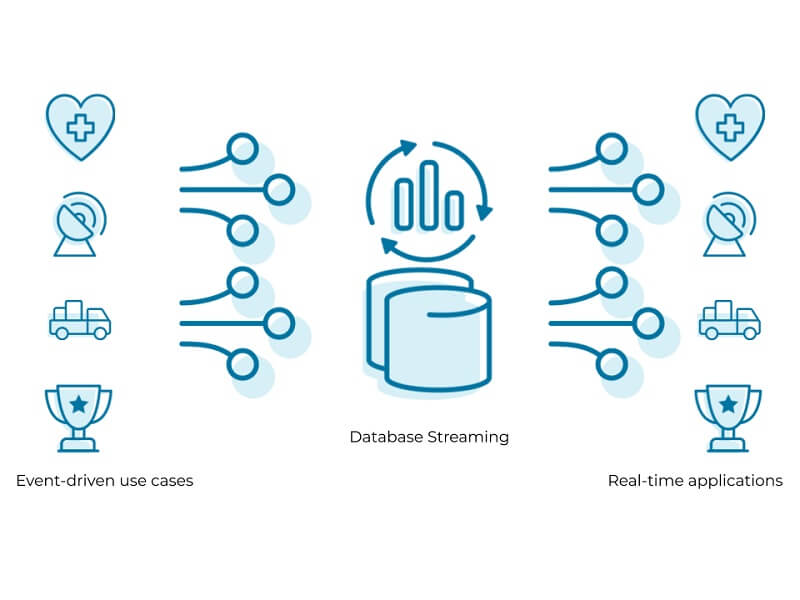
Data Pipeline sẽ được thực hiện bởi một quy trình có các bước cơ bản sau:
Thông thường, dữ liệu sẽ được lấy từ nhiều nguồn khác nhau, bao gồm cả dữ liệu có cấu trúc và không có cấu trúc. Khi dữ liệu phát trực tuyến, các dữ liệu thô sẽ được gọi là một nhà sản xuất, nhà xuất bản hay đơn giản là người gửi.
Mặc dù, doanh nghiệp hoàn toàn có thể lựa chọn trích xuất dữ liệu khi đã sẵn sàng xử lý dữ liệu đó nhưng họ vẫn sẽ đưa dữ liệu thô vào kho chứa xử lý đám mây trước. Việc làm này sẽ giúp doanh nghiệp có thể cập nhật lịch sử dữ liệu khi họ cần điều chỉnh công việc xử lý.

Sang bước tiếp theo sẽ là tiến trình chuyển đổi dữ liệu. Tại đó, một loạt các thao tác sẽ được xử lý để chuyển đổi dữ liệu thành định dạng khi mà kho dữ liệu gửi các yêu cầu. Công việc này sẽ hoàn toàn được tự động hóa và thay thế cho việc được lặp đi lặp lại. Ví dụ thực tế như bản báo cáo kinh doanh, dữ liệu ở đây sẽ được yêu cầu phải sạch và chuyển đổi một cách thống nhất với nhau.

Tất cả những dữ liệu chuyển đổi sẽ được lưu trữ ngay tại trong kho của dữ liệu. Đây là nơi sẽ được giới thiệu hoặc trình bày cho đối tác của doanh nghiệp. Khi dữ liệu được phát trực tuyến, những dữ liệu chuyển đổi sẽ được gọi là người tiêu dùng, người nhận hay người đăng ký.
Khi khối lượng dữ liệu ngày càng phát triển, yêu cầu doanh nghiệp phải liên tục nâng cao công cụ để thực hiện quản lý. Thông thường, một Data Pipeline sẽ được ứng dụng vào các công đoạn cơ bản sau:
Tất cả các dữ liệu sẽ được trình bày thông qua sơ đồ, hình ảnh, biểu đồ hay infographic,… Mọi thông tin được biểu diễn một cách cụ thể và có màu sắc này sẽ giúp người khách hàng hiểu được mối tương quan giữa dữ liệu và insights.

Machine Learning được biết đến là một nhánh của trí tuệ nhân tạo hay khoa học máy tính. Nó được tập trung trong việc sử dụng dữ liệu hay thuật toàn để bắt chước cách học của con người. Bằng việc sử dụng các phương pháp thống kê, các thuật toán này sẽ được dùng để phân loại hay dự đoán và thực hiện về tìm hiểu dữ liệu.
Tóm lại, Data Pipeline là một cách mạng của công nghệ giúp cho các doanh nghiệp có thể xử lý được một khối lượng dữ liệu lớn nhưng vẫn giữ tiến độ ổn định và hiệu quả. Mong rằng, bài viết của timviec365 đã giúp các bạn hiểu rõ hơn về Data Pipeline là gì và các định dạng của nó.
Đồng bộ dữ liệu là gì? Tại sao người dùng nên đồng bộ hóa dữ liệu?








 Trả lời
Trả lời